Algoritmo de calificación de participaciones: Valorando el discurso textual en función de su perspicuidad
3
About :
Algoritmo de calificación de participaciones: Valorando el discurso textual en función de su perspicuidad
Por Enio...

Ser objetivos a la hora de evaluar un mensaje o argumento expresado en una pieza de información textual no es fácil. Por una parte, tenemos que los enfoques de investigación cualitativos favorecen la intersubjetividad del investigador a la hora de hacer un análisis de contenido. En ellos no es un problema extraer categorías valiéndose de la propia interpretación y opinión del investigador. Este tipo de análisis permite ir más allá y descubrir significados más profundos, ciertamente. Sin embargo, tambien es cierto que en él es difícil replicar resultados, que es señal de objetividad y cientificidad.
En escenarios que no son de investigación científica también interesa valorar de manera objetiva la información textual que tenga intención comunicativa. Un ejemplo de ello tiene que ver con calificar los comentarios que hacen los usuarios en un foro de internet, de modo que se pueda determinar qué comentarios son realmente valiosos.
Esto es un problema informático muy común, pues en la internet funcionan millones de servicios cuyo éxito se basa en saber distinguir buenos comentarios de otros y ello va intergrado en los motores de busqueda, web crawlers, etc. El asunto se complica más cuando el valor debe extraerse exclusivamente del contenido del mensaje y no de metainformación que lo rodea, como los votos o "likes", los reblogueos, respuestas, visitas, reacciones que pueda recibir un comentario.
Ahora bien, un problema similar se ha presentado en los servidores de Discord donde se realizan actividades como foros e intercabios usando los canales de voz y texto y en las cuales interese determinar los méritos de los usuarios con base en sus participaciones. Este es precisamente el caso de la comunidad @STEM-Espanol y los webinars periódicos que se realizan allí, conocidos como conversatorios. En ellos se otorgan recompensas a los usuarios que asistan al encuentro y participen activamente en el canal de texto. Al principio, los usuarios se premiaban al azar, pero pronto se descubrió que esto no va con el espíritu meritocrático ni parece muy científico tampoco, por lo que pronto se pensó en una solución.
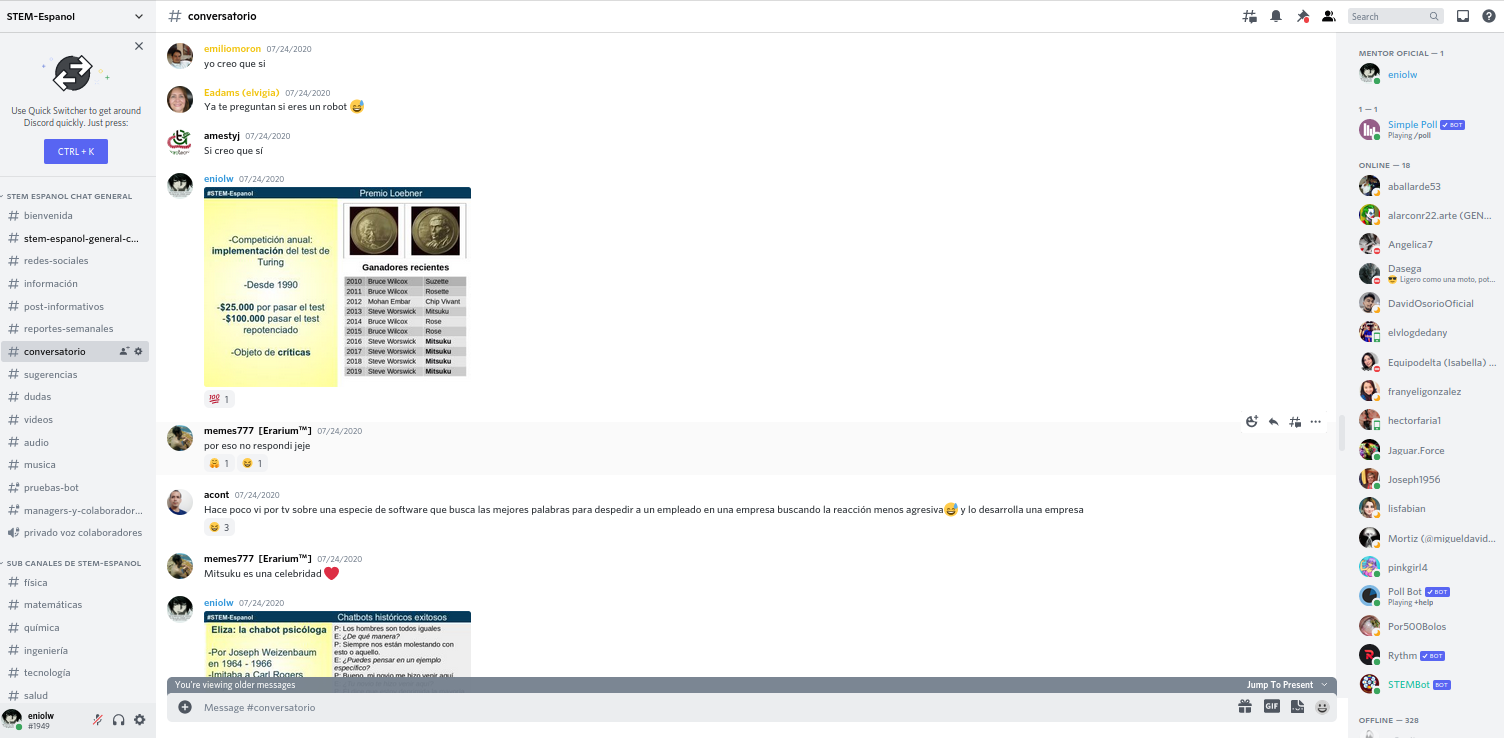
⬆️ Imagen 1: Un conversatorio (webinar) de STEM-Espanol a través de Discord en el que tuve la ocasión de moderar.
En el vídeo que acompaña este post realizo una descripción de una solución propuesta a ese problema, la cual consiste en un algoritmo que ya está implementado e incluido como funcionalidad en el bot de moderación de la comunidad, el cual auxilia el proceso de seguimiento y valoración de las participaciones de los usuarios durante los conversatorios.
Podemos ver que este no es un problema nuevo y que, en una ocasión, el usuario @lemouth tuvo que introducir algún tipo de criterio que le permitiera cuantificar el nivel de compromiso de los autores de STEMSocial (en ese entonces SteemSTEM) con respecto a la comunidad. Tomó como base los comentarios realizados por los usuarios en los posts curados por STEMSocial. Debe destacarse que los comentarios debían poseer un mínimo de longitud para que calificaran y tributaran al indicador de compromiso.
Este tipo de análisis de contenido es de nivel eminentemente sintáctico. Tiene que ver también con la lexicometría y básicamente cuantifica en función del número de elementos textuales, tales como los caracteres, las sílabas, las palabras, las frases, los párrafos, etc. Este tipo de análisis no es muy difícil de implementar, dependiendo de lo que se proponga, y resulta ser bastante confiable en término de objetividad. Su limitación, no obstante, es que no toma en cuenta los elementos semánticos, de modo que no es necesariamente asertivo. Puede haber un mensaje corto que transmita mucha información valiosa, en contraposición a otro mensaje extenso que transmita poca información de valor.
Sin embargo, descubrí una forma de mejorar este enfoque para el algoritmo que propuse. A valor de la extensión del comentario se puede sumar su índice de legibilidad o perspicuidad. La perspicuidad, según la DRAE, es la "cualidad de perspicuo", es decir, que esta escrito con estilo de manera inteligible o, en otras palabras, que puede ser entendido.
Existen varios índices de legibilidad en español. Uno de ellos es el Índice de perspicuidad de Szigriszt-Pazos, propuesto por Francisco Szigriszt-Pazos en su trabajo de tesis doctoral en 1993. Es una adaptación de la ecuación de Flesh que hace el mismo trabajo pero para el idioma inglés. Recordemos que los idiomas pueden variar mucho en lo que se refiere a la densidad de información y el numero de símbolos y elementos textuales para representar la información, de modo que es necesario hacer adaptaciones. La fórmula de Szigriszt-Pazos es la siguiente:
P = 206.835 - 62.3*S/p - p/FDonde P es el Índice de perspicuidad, S es el número de sílabas, p es el número de palabras y F es el número de frases.
El índice de Szigriszt-Pazos resulta ser oportuno, pues es usado más allá del área escolar y puede describir la dificultad para leer textos científicos y técnicos, que sería lo propio de un comentario valioso en el contexto de un evento de nivel académico como resulta ser un conversatorio de STEM-Español. Además, ha sido revisado más recientemente y ahora lo acompaña una segunda forma de interpretación conocida como la Escala INFLESZ, la cual que se inserta a continuación:
| Perspecuidad | INFLESZ |
|---|---|
| 0 < p ≤ 40 | Muy difícil |
| 40 < p ≤ 55 | Algo difícil |
| 55 < p ≤ 60 | Normal |
| 65 < p ≤ 80 | Bastante fácil |
| 80 < p ≤ 100 | Muy fácil |
De modo que a más bajo el índice, mayor dificultad para leer, mientras que a más alto sea, menos dificultad para leer. Esto es interesante pues es un método objetivo que puede ayudar a discriminar el nivel de formalidad y tecnicismo con que esta escrito un comentario. Se espera que los comentarios dentro de un tópico de STEM tengan un nivel mínimo de tecnicismo, no solo por las palabras académicas que muy rara la vez se utilizan en la comunicación oral y en un contexto informal, sino por los léxicos científicos y técnicos que existen que pueden ser bastante extensos en algunos casos, como los nombres científicos en latín, por ejmplo.
De modo que de eso se trata la solución propuesta. A continuación incorporo una implementación realizada en Python 3:
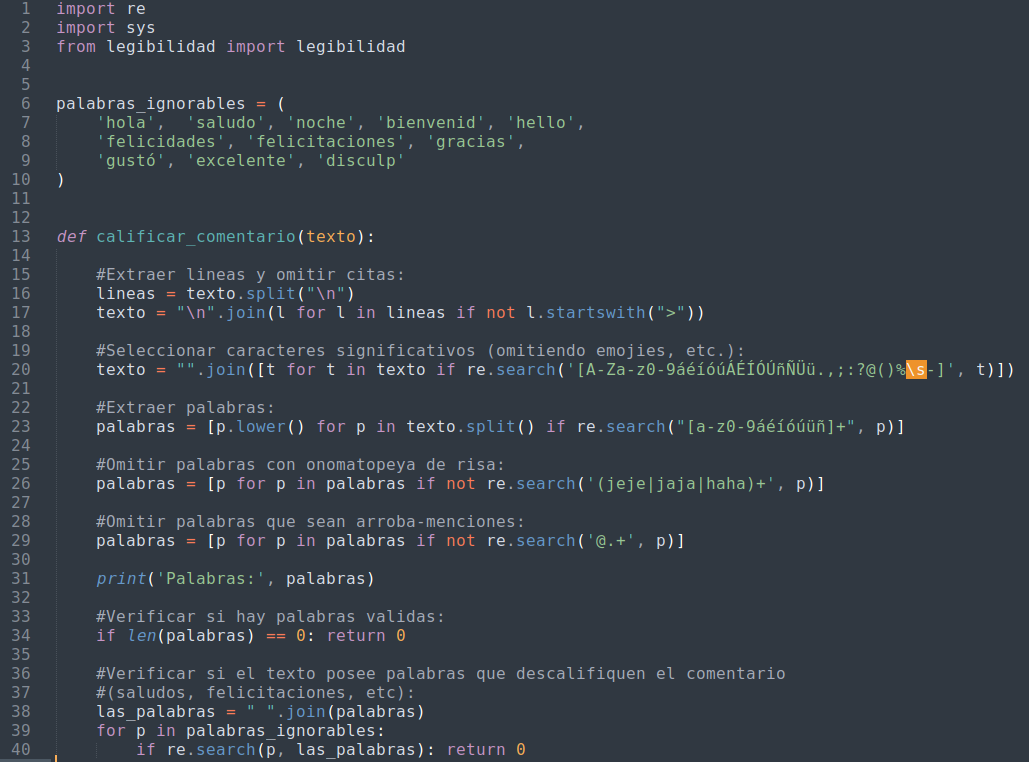
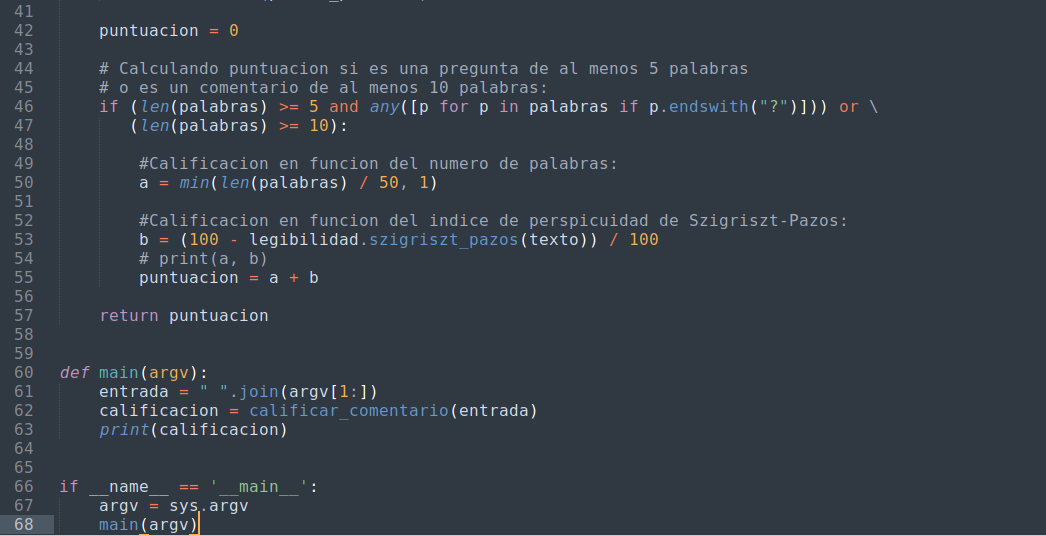
⬆️ Imagen 2: Una implementación del algoritmo en lenguaje Python 3.
Como vemos, el código esta comentado para describir el algoritmo. Primero se ha importado el modulo legibilidad (línea 3) que contiene muchas fórmulas para medir la legibilidad. Este módulo es de Alexander Ayasca. Los módulos re y sys son estándar.
El trabajo como tal lo hace la función calificar_comentario (líneas 13-57). Primero hace un preprocesamiento de la entrada al dividir el texto de entrada en líneas a fin de seleccionar aquellas que no consistan en citas (línea 16-17). Esto se hace porque anteriormente en Discord cuando se respondía un mensaje de otro usuario en un canal, lo que la aplicación hacía era citar el mensaje respondido, incluyéndolo en el mensaje que se escribe. El texto citado no interesa, ya que no es el contenido del participante que escribe el mensaje.
Tras esto se seleccionan los caracteres significativos (línea 20). Esto básicamente va a permitir eliminar los emojies y otros símbolos unicode que no interesen. Se extraen las palabras (línea 23) y luego se excluyen las palabras que sean onomatopeyas de risa, como "jaja" (línea 26), algo muy común y esperable en las conversaciones de texto. También se omiten palabras que sean arroba-menciones, como @eniolw (línea 29). Se entiende que estas palabras no aportan mucho valor.
Ahora bien, de existir palabras calificables, entonces se verifica si hay palabras que descalifiquen el comentario por completo (línea 38-40). Esto ha sido un criterio metodológico del autor para añadir un poco de consciencia semántica y mejorar los filtros. Básicamente se considerarán comentarios descalificados a aquellos que posean palabras clave como "buenas noches", "felicitaciones", "bienvenido", etc., ya que se entiende que estos son mensajes de cortesía, mas no aportes en el tópico.
Finalmente, se determina si es una pregunta o no. Las preguntas deben poseer el símbolo "?" y tener al menos 5 palabras, de otro modo deben ser comentarios de al menos 10 palabras (línea 46). De ser un comentario válido, se computa el valor de dos términos: la extensión del mensaje (línea 50) y el índice de perspicuidad (línea 53). Estos se suman y se retornan. El valor sería entonces manejado por otras rutinas que se encargarán de acumular, ordenar y mostrar los resultados.
Se espera que los ganadores sean aquellos que posean mayor puntuación (la primera versión que el bot implementó, por cierto, daba más prioridad al número de comentarios válidos que al coeficiente de valor).
Como se mencionó anteriormente, esta metodología es un buen comienzo para tratar de valorar las participaciones de los usuarios de manera objetiva y confiable, esto es, que dependa enteramente del contenido del mensaje sin intervención subjetiva de algún evaluador humano, además de que el valor es computado por un algoritmo y es reproducible, esto es, que otra implementación del algoritmo debería dar los mismos resultados.
Desde luego, hay muchísimas cosas por mejorar, entre ellas, el tratamiento superficial que se hace de la semántica del mensaje. Esto es sumamente difícil de trabajar o por lo menos requiere muchas líneas de código y algunas cuantas librerías extra, pero sería útil e interesante. Es un desafío dentro del área de Procesamiento de Lenguaje Natural (NLP).
De igual forma, la metodología y el algoritmo como tal pueden seguir siendo mejorados para prevenir exploits, algo que normalmente no se esperaría de parte de una comunidad de STEM, pero en la programación hay ciertos criterios de calidad del software según los cuales hay que 'desconfiar' de los usuarios, no por malas intenciones, sino también por errores involuntarios. En todo caso, el script mostrado arriba es una implementación demostrativa del algoritmo.
Espero les haya gustado el vídeo y el post. Comparte tus opiniones, serán bien recibidas.
ALGUNAS FUENTES
- Sobre el Índice de perspicuidad de Szigriszt-Pazos.
- Sobre la Escala INFLESZ.
- Sobre la Escala INFLESZ.
- Post de @lemouth:Towards a reputation system suitable for SteemSTEM (Hacia un sistema de reputacion adecuado para SteemSTEM).
- Post de @eniolw:💻🤖💫 STEMBot: Consideraciones en torno al desarrollo y lanzamiento del bot de moderación para Discord como contribución para el fortalecimiento de nuestra comunidad de Steemit.
- Repositorio de GitHub y archivo del script.
Si estás interesado en más temas sobre Ciencia, Tecnología, Ingeniería y Matemáticas (STEM, siglas en inglés), consulta las etiquetas #STEM-Espanol y #STEMSocial, donde puedes encontrar más contenido de calidad y también hacer tus aportes. Puedes unirte al servidor de Discord de STEM-Espanol para participar aún más en nuestra comunidad y consultar los reportes semanales publicados por @STEM-Espanol.

NOTAS ACLARATORIAS
- A menos que se indique lo contrario, las imágenes son del autor.
- En el vídeo mencioné y pronuncié "perspecuidad" en lugar de "perspicuidad" que es lo correcto. La palabra era nueva para mí :)
- En el vídeo comento que actualizaría el post para incluir el link al repositorio de GitHub con el script. Ya está hecho (ver más arriba en sección de fuentes).

Show more
Tags :
Woo!
This creator can upvote comments using 3speak's stake today because they are a top performing creator!
Leave a quality comment relating to their content and you could receive an upvote
worth at least a dollar.
Their limit for today is $0!
Their limit for today is $0!

35 views
2 years ago
$

17 views
2 years ago
$

12 views
2 years ago
$

5 views
2 years ago
$

16 views
2 years ago
$
More Videos

3 views
4 months ago
$

7 views
2 months ago
$

12 views
a year ago
$

8 views
2 years ago
$

0 views
5 hours ago
$

10 views
a year ago
$

9 views
10 months ago
$

4 views
2 years ago
$

9 views
2 years ago
$

3 views
2 years ago
$

7 views
2 years ago
$

79 views
3 years ago
$

5 views
4 years ago
$

1 views
2 years ago
$

20 views
2 years ago
$
5 views
2 years ago
$

9 views
2 years ago
$

1 views
2 years ago
$

20 views
2 years ago
$

8 views
9 months ago
$

8 views
4 months ago
$

6 views
10 months ago
$

10 views
2 years ago
$

6 views
a year ago
$

4 views
2 weeks ago
$
Comments:
Reply:
To comment on this video please connect a HIVE account to your profile: Connect HIVE Account